
AI excels at code competitions, struggles with real work
What CodeForces rankings reveal about AI capabilities


Author’s note: This analysis was originally part of a previous post, but it was buried at the bottom and I wanted to feature it more prominently. So I removed it from there, expanded it, and put it here. But sorry if you’re seeing this twice.
~
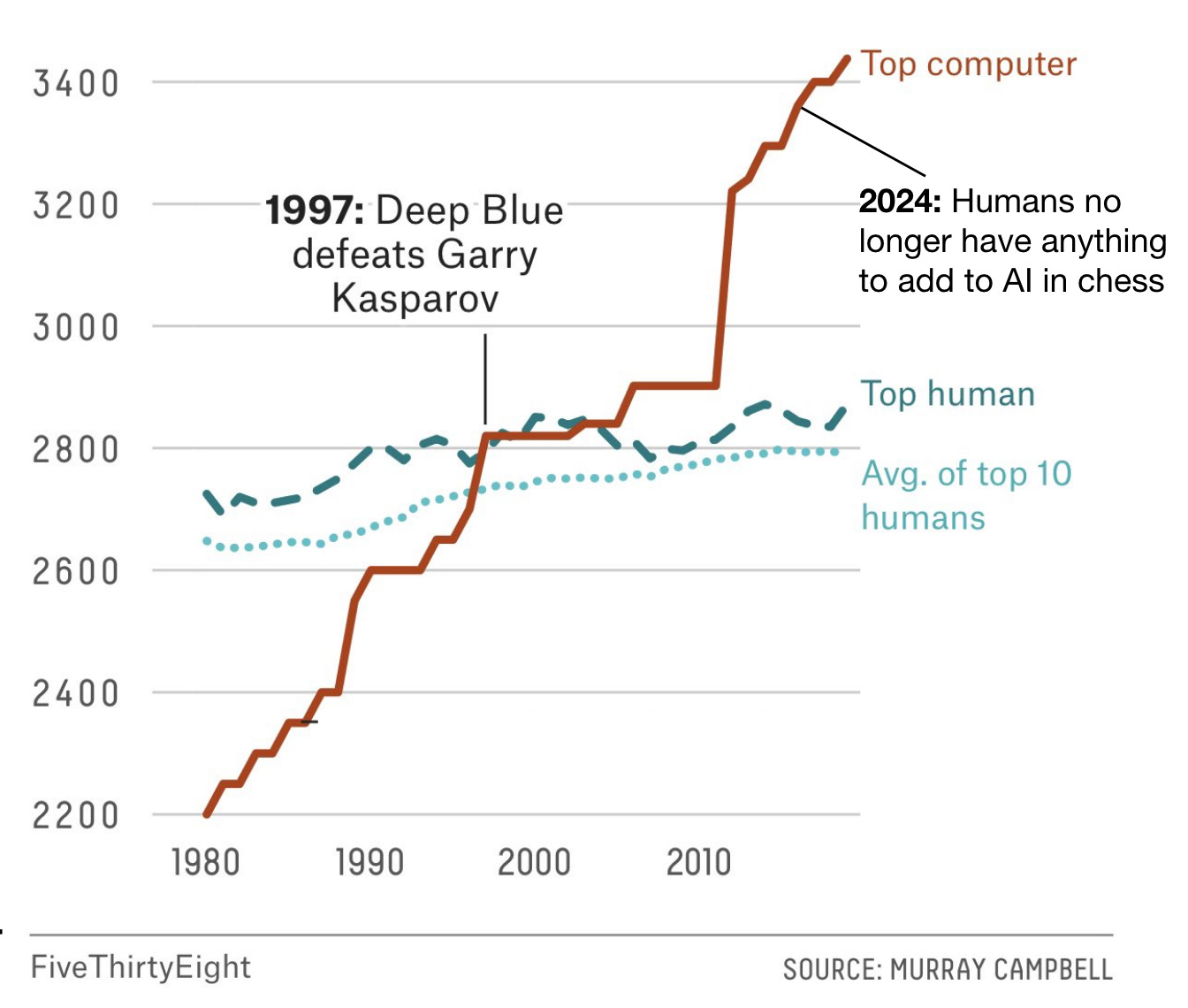
When IBM's Deep Blue beat chess champion Garry Kasparov in 1997, it was a notable milestone in the development of AI. Today, AI systems are beginning to achieve similar feats in the world of competitive programming — but the implications for automating real-world software development are more complex.
The CodeForces achievement
I covered previously that Sam Altman (along with OpenAI Chief Product Officer Kevin Weil) gave a Q&A at the University of Tokyo Center for Global Education, which among many topics got into some details about reasoning models.
In particular, Altman mentioned massive improvement at competitive programming. Competitive programming is an e-sport where programmers compete to solve algorithmic puzzles under fairly tight time constraints. CodeForces, one of the leading platforms in this space, hosts regular contests, usually in two-hour rounds.
Based on how one does, competitors at CodeForces rating on an Elo rating system, like Chess ratings. A rating of 1900+ puts you in the top 1%, which typically requires the skills of a strong software engineer at a major tech company. Top 50 CodeForces contestants typically have ratings above 3000 and are algorithm specialists at companies like Google and Facebook.
As far as I know, OpenAI’s LLMs have not actually competed directly on CodeForces against humans. But OpenAI did publish a paper on February 3 which outlined a mock CodeForces dataset:
To assess our models’ competitive programming abilities, we simulated CodeForces contests under conditions that closely mirrored real competitions. This included using the full test suite for each problem and enforcing appropriate time and memory constraints for solutions.
Our evaluation focused on Division 1 contests from 2024 and December 2023, ensuring all test contests occurred after the data cut-off[…] Additionally, we conducted a contamination check as a sanity measure, leveraging the OpenAI embedding API to verify that test problems had not been seen during training.
This dataset lets OpenAI compare their models to human scores. Sam Altman notes their very first reasoning model was in the top one million at competitive programming on this dataset. OpenAI’s most recent (but not yet released) o3 model is reported to be in the top 175. In the Q&A, Altman mentioned seeing internal benchmarks where their model placed in the top 50, and Altman thinks OpenAI will beat top human performance by the end of the year.
Here’s a chart of this progress to date:
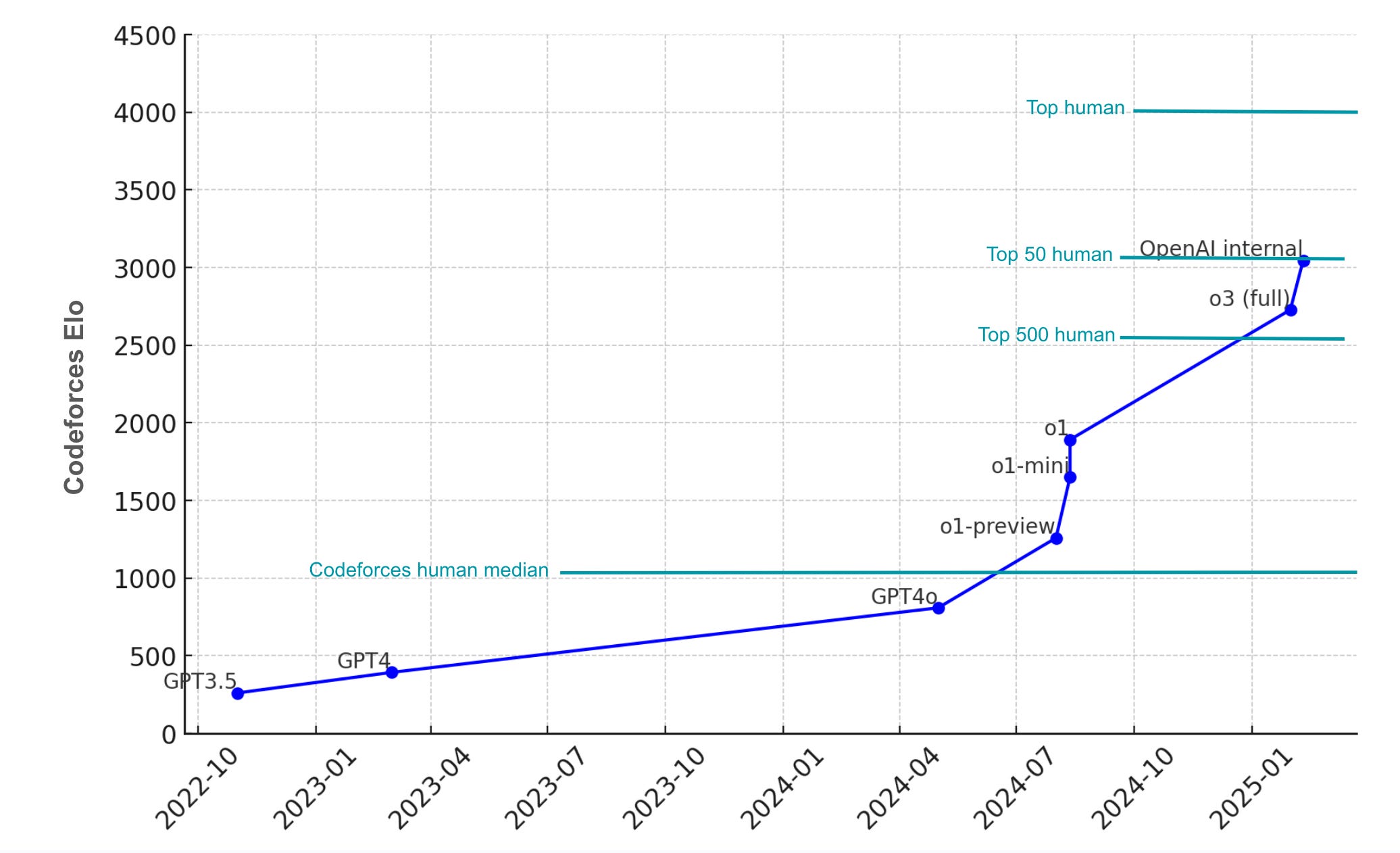
Compare that graph to the rise in ELO score among chess computers, where chess engines rapidly rose to human-level skill and then eventually surpassed human skill, to where today humans add absolutely no value compared to what chess engines can come up with:
Human vs. AI approaches
So does this mean that AI is about to become a superhuman engineer and automate computer programming? Not quite yet.
One key thing to understand in these CodeForces challenges is that humans are under intense time pressure. OpenAI says they were “enforcing appropriate time and memory constraints for solutions”, but I think this means that the AI received the same amount of time as humans, which is an awful lot of time for the AI. This was enough time to generate over 1000 potential solutions before using reasoning to decide which single solution to submit.
This is a key difference between human and AI approaches. Humans do not have the time to generate over 1000 candidate solutions. A human programmer instead looks at a problem and quickly intuits the correct algorithm based on years of experience and pattern recognition. They'll write one or two solutions at most. AI, in contrast, is much less efficient per attempt but makes up for it with speed and volume. If AI was restricted to type code at a typical human speed, it would lose CodeForces competitions to humans badly. This distinction may matter if it suggests AI still lacks some deep understanding that humans have.
But to be clear, this isn’t just trial and error, and the AI isn’t just brute forcing the solutions — there’s too many possible options to do that. AI definitely shows genuine understanding. And in the real world, the AI will just genuinely be faster — this is a real advantage AI actually has.
Current limitations
So how good is AI at software engineering? METR, an independent evaluation org, put this to the test in November and found different AI systems (colored lines) outperforming expert human programmers (black line) until a bit before the four hour mark, and then underperforming after that:
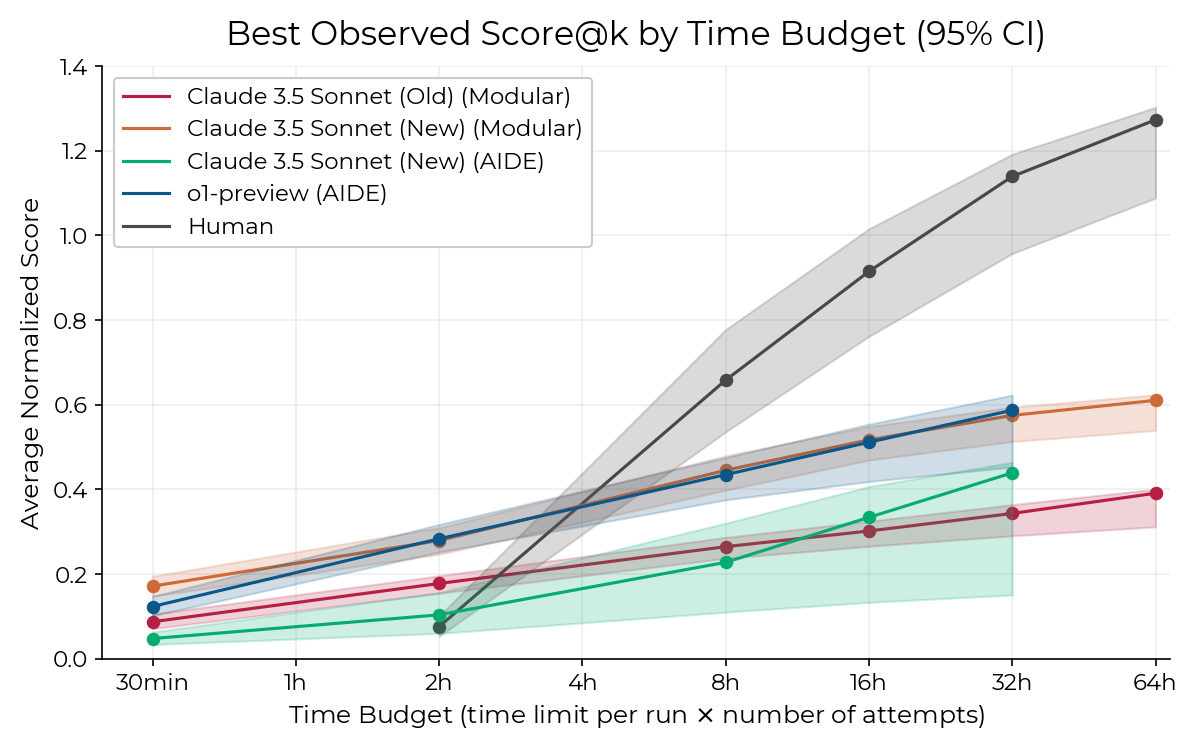
This means we’re still a ways away from fully automated software engineers. A fully autonomous coding agent - one that can independently brainstorm, debug, test, and integrate entire systems - is a lot more complex than what we currently have. Altman says in the Q&A that such systems are still a major research challenge.
As another illustration, it was interesting to see in the o3-mini system card that despite OpenAI models being able to pass OpenAI research engineer interviews with 93% accuracy…
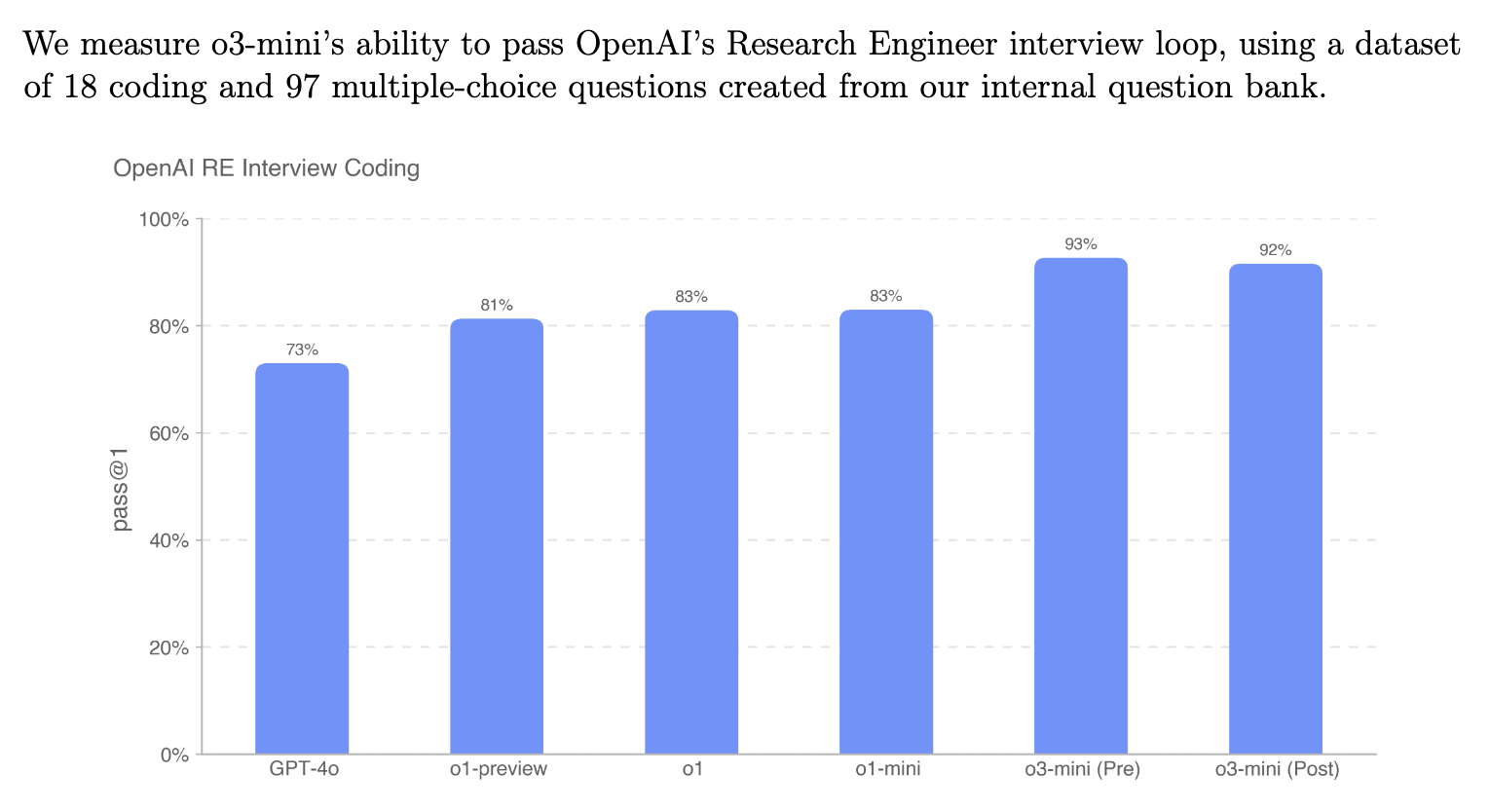
…the models still were not skilled at replicating pull request contributions by OpenAI employees:
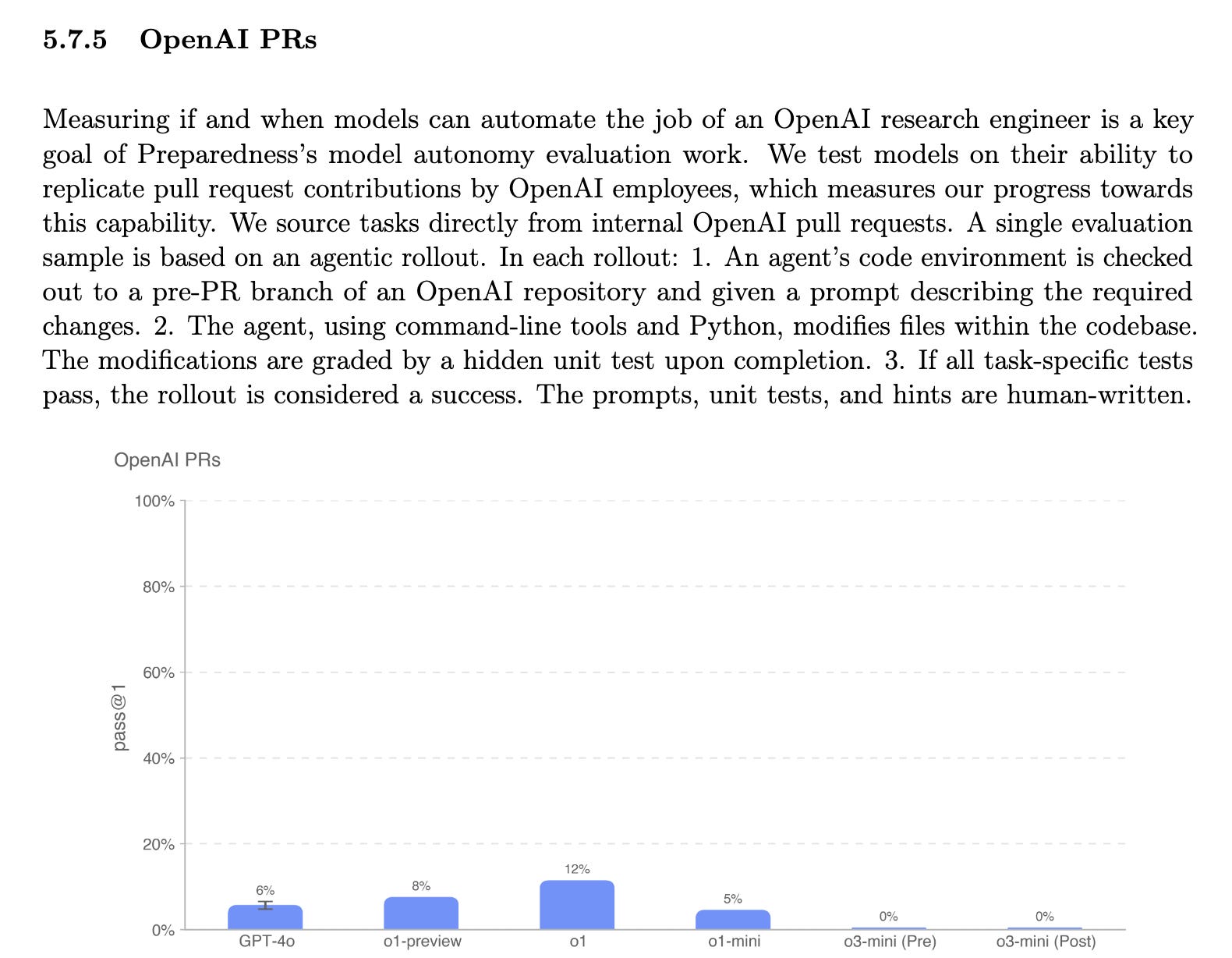
Implications
The rapid progress in competitive programming capabilities has several important implications:
The jump from top 1M to top 50 in competitive programming on CodeForces happened faster than many experts predicted, suggesting we may need to revise timeline estimates for other AI capabilities.
If AI becomes able to replace or notably augment human software engineers that could create a feedback loop where AI could accelerate the development of future AI systems. This could make AI timelines even shorter.
Significant uncertainty remains about how quickly these capabilities will develop. While OpenAI's progress is impressive, it is hard to extrapolate from CodeForces performance to real-world software development capabilities. The gap between solving well-defined algorithmic puzzles and managing complex software projects remains substantial.
While AI excels at well-defined, time-limited programming tasks, it still struggles with longer-term software development challenges. This suggests that near-term risks from AI systems currently come not from complete automation, but from augmentation of existing capabilities. This has ramifications for everything from software infrastructure development to cybersecurity.
The trajectory of AI progress in competitive programming offers both a warning and a reality check. While the pace of improvement has been remarkable, limitations in areas requiring longer-term reasoning and system design suggest we're still in a transition period. This gives policymakers and organizations time to adapt, but that window may be shorter than previously assumed.
Further understanding of both the capabilities and limitations of current systems is crucial for making informed decisions about AI policy and investment.
What do you think of the benchmarks SWE-bench or SWE-bench verified for tracking real world software engineering skill? Those scores are rising, but I'm not sure how easy it is to game them.
Has anyone ever tested AI programming at tasks that require numerical analysis? Example: systems of nonlinear differential equations, in which the number of iterations need to be limited as a function of how quickly results begin diverging, or whether convergence is rooted in reality?